NVIDIA NeMo Framework

Especificacions
- Nom del producteMarc de treball NVIDIA NeMo
- Plataformes afectades: Windows, Linux, macOS
- Versions afectades: Totes les versions anteriors a la 24
- Vulnerabilitat de seguretat: CVE-2025-23360
- Puntuació base de l'avaluació de riscos: 7.1 (CVSS v3.1)
Instruccions d'ús del producte
Instal·lació de l'actualització de seguretat:
Per protegir el vostre sistema, seguiu aquests passos:
- Baixeu la darrera versió de la pàgina de versions de NeMo-Framework-Launcher al GitHub.
- Aneu a Seguretat del producte NVIDIA per obtenir més informació.
Detalls de l'actualització de seguretat:
L'actualització de seguretat soluciona una vulnerabilitat a NVIDIA NeMo Framework que podria provocar l'execució de codi i la pèrdua de dades.amperrant.
Actualització de programari:
Si feu servir una versió anterior de la branca, es recomana actualitzar-la a la darrera versió per solucionar el problema de seguretat.
Acabatview
NVIDIA NeMo Framework és un marc de treball d'IA generativa escalable i natiu del núvol creat per a investigadors i desenvolupadors que treballen en Grans models lingüístics, Multimodal i IA de la parla (p. ex Reconeixement automàtic de la veu i Text a veu). Permet als usuaris crear, personalitzar i implementar de manera eficient nous models d'IA generatius aprofitant el codi existent i els punts de control de models preentrenats.
Instruccions de configuració: Instal·leu el marc de treball NeMo
NeMo Framework proporciona suport integral per al desenvolupament de models de llenguatge gran (LLM) i models multimodals (MM). Ofereix la flexibilitat per ser utilitzat localment, en un centre de dades o amb el vostre proveïdor de núvol preferit. També admet l'execució en entorns habilitats per a SLURM o Kubernetes.

Curació de dades
Curador de NeMo [1] és una biblioteca de Python que inclou un conjunt de mòduls per a la mineria de dades i la generació de dades sintètiques. Són escalables i optimitzats per a GPU, cosa que els fa ideals per a la curació de dades de llenguatge natural per entrenar o ajustar LLM. Amb NeMo Curator, podeu extreure de manera eficient text d'alta qualitat de dades en brut extenses. web fonts de dades.
Formació i personalització
NeMo Framework proporciona eines per a la formació i la personalització eficients de LLMs i models multimodals. Inclou configuracions predeterminades per a la configuració del clúster de càlcul, la descàrrega de dades i els hiperparàmetres del model, que es poden ajustar per entrenar amb nous conjunts de dades i models. A més del preentrenament, NeMo admet tant tècniques d'ajustament fi supervisat (SFT) com d'ajustament fi eficient de paràmetres (PEFT) com ara LoRA, Ptuning i més.
Hi ha dues opcions disponibles per iniciar l'entrenament a NeMo: utilitzant la interfície de l'API de NeMo 2.0 o amb NeMo Run.
- Amb NeMo Run (recomanat): NeMo Run proporciona una interfície per optimitzar la configuració, l'execució i la gestió d'experiments en diversos entorns informàtics. Això inclou l'inici de tasques a l'estació de treball localment o en grans clústers, tant amb SLURM com amb Kubernetes en un entorn de núvol.
- Preentrenament i inici ràpid de PEFT amb NeMo Run
- Usant l'API de NeMo 2.0: Aquest mètode funciona bé amb una configuració senzilla que implica models petits o si us interessa escriure el vostre propi carregador de dades personalitzat, bucles d'entrenament o canviar capes de models. Us ofereix més flexibilitat i control sobre les configuracions i facilita l'ampliació i la personalització de les configuracions mitjançant la programació.
-
TraInici ràpid amb l'API de NeMo 2.0
-
Migració de l'API de NeMo 1.0 a NeMo 2.0
-
Alineació
- Alineador de NeMo [1] és un conjunt d'eines escalable per a l'alineació eficient de models. El conjunt d'eines és compatible amb algoritmes d'alineació de models d'última generació com ara SteerLM, DPO, Reinforcement Learning from Human Feedback (RLHF) i molts més. Aquests algoritmes permeten als usuaris alinear models de llenguatge per ser més segurs, inofensius i útils.
- Tots els punts de control de NeMo-Aligner són compatibles amb l'ecosistema NeMo, cosa que permet una major personalització i desplegament d'inferències.
Flux de treball pas a pas de les tres fases de RLHF en un petit model GPT-2B:
- Formació SFT
- Formació en models de recompensa
- Formació PPO
A més, demostrem que donem suport a diversos altres mètodes d'alineació nous:
- DPO: un algorisme d'alineació lleuger en comparació amb RLHF amb una funció de pèrdua més simple.
- Auto-Reproducció Ajustament fi (SPIN)
- SteerLM: una tècnica basada en SFT condicionada, amb sortida dirigible.
Consulteu la documentació per obtenir més informació: Documentació d'alineació
Models multimodals
- NeMo Framework proporciona programari optimitzat per entrenar i implementar models multimodals d'última generació en diverses categories: models de llenguatge multimodal, fonaments de visió-llenguatge, models de text a imatge i més enllà de la generació 2D mitjançant camps de radiància neuronal (NeRF).
- Cada categoria està dissenyada per satisfer necessitats i avenços específics en el camp, aprofitant models d'avantguarda per gestionar una àmplia gamma de tipus de dades, com ara text, imatges i models 3D.
Nota
Estem migrant la compatibilitat amb models multimodals de NeMo 1.0 a NeMo 2.0. Si voleu explorar aquest domini mentrestant, consulteu la documentació de la versió NeMo 24.07 (anterior).
Implementació i inferència
NeMo Framework ofereix diverses rutes per a la inferència LLM, adaptant-se a diferents escenaris de desplegament i necessitats de rendiment.
Implementació amb NVIDIA NIM
- NeMo Framework s'integra perfectament amb eines de desplegament de models a nivell empresarial a través de NVIDIA NIM. Aquesta integració funciona amb NVIDIA TensorRT-LLM, cosa que garanteix una inferència optimitzada i escalable.
- Per obtenir més informació sobre NIM, visiteu la pàgina web d'NVIDIA weblloc.
Implementa amb TensorRT-LLM o vLLM
- NeMo Framework ofereix scripts i API per exportar models a dues biblioteques optimitzades per a inferència, TensorRT-LLM i vLLM, i per implementar el model exportat amb el servidor d'inferència NVIDIA Triton.
- Per a escenaris que requereixen un rendiment optimitzat, els models NeMo poden aprofitar TensorRT-LLM, una biblioteca especialitzada per accelerar i optimitzar la inferència LLM a les GPU NVIDIA. Aquest procés implica convertir els models NeMo a un format compatible amb TensorRT-LLM mitjançant el mòdul nemo.export.
- Desplegament de LLM acabatview
- Implementar models de llenguatge grans de NeMo amb NIM
- Implementa models de llenguatge grans de NeMo amb TensorRT-LLM
- Implementa els models de llenguatge gran de NeMo amb vLLM
Models suportats
Grans models lingüístics
| Grans models lingüístics | Preentrenament i SFT | PEFT | Alineació | Convergència de formació del 8è PM | TRT/TRTLLM | Converteix a i des de Cara d'abraçada | Avaluació |
|---|---|---|---|---|---|---|---|
| Llama3 8B/70B, Llama3.1 405B | Sí | Sí | x | Sí (parcialment verificat) | Sí | Tots dos | Sí |
| Mixtral 8x7B/8x22B | Sí | Sí | x | Sí (sense verificar) | Sí | Tots dos | Sí |
| Nemotró 3 8B | Sí | x | x | Sí (sense verificar) | x | Tots dos | Sí |
| Nemotró 4 340B | Sí | x | x | Sí (sense verificar) | x | Tots dos | Sí |
| Baichuan2 7B | Sí | Sí | x | Sí (sense verificar) | x | Tots dos | Sí |
| XatGLM3 6B | Sí | Sí | x | Sí (sense verificar) | x | Tots dos | Sí |
| Gemma 2B/7B | Sí | Sí | x | Sí (sense verificar) | Sí | Tots dos | Sí |
| Gemma2 2B/9B/27B | Sí | Sí | x | Sí (sense verificar) | x | Tots dos | Sí |
| Mamba2 130M/370M/780M/1.3B/2.7B/8B/ Hybrid-8B | Sí | Sí | x | Sí (sense verificar) | x | x | Sí |
| Phi3 mini 4k | x | Sí | x | Sí (sense verificar) | x | x | x |
| Qwen2 0.5B/1.5B/7B/72B | Sí | Sí | x | Sí (sense verificar) | Sí | Tots dos | Sí |
| StarCoder 15B | Sí | Sí | x | Sí (sense verificar) | Sí | Tots dos | Sí |
| StarCoder2 3B/7B/15B | Sí | Sí | x | Sí (sense verificar) | Sí | Tots dos | Sí |
| BERT 110M/340M | Sí | Sí | x | Sí (sense verificar) | x | Tots dos | x |
| T5 220M/3B/11B | Sí | Sí | x | x | x | x | x |
Models de llenguatge de visió
| Models de llenguatge de visió | Preentrenament i SFT | PEFT | Alineació | Convergència de formació del 8è PM | TRT/TRTLLM | Converteix a i des de Cara d'abraçada | Avaluació |
|---|---|---|---|---|---|---|---|
| NeVA (LLaVA 1.5) | Sí | Sí | x | Sí (sense verificar) | x | Des de | x |
| Llama 3.2 Visió 11B/90B | Sí | Sí | x | Sí (sense verificar) | x | Des de | x |
| LLaVA Next (LLaVA 1.6) | Sí | Sí | x | Sí (sense verificar) | x | Des de | x |
Incrustació de models
| Incrustació de models de llenguatge | Preentrenament i SFT | PEFT | Alineació | Convergència de formació del 8è PM | TRT/TRTLLM | Converteix a i des de Cara d'abraçada | Avaluació |
|---|---|---|---|---|---|---|---|
| SBERT 340M | Sí | x | x | Sí (sense verificar) | x | Tots dos | x |
| Llama 3.2 Incrustació 1B | Sí | x | x | Sí (sense verificar) | x | Tots dos | x |
Models de la Fundació Mundial
| Models de la Fundació Mundial | Post-entrenament | Inferència accelerada |
|---|---|---|
| Cosmos-1.0-Difusió-Text2Món-7B | Sí | Sí |
| Cosmos-1.0-Difusió-Text2Món-14B | Sí | Sí |
| Cosmos-1.0-Difusió-Video2World-7B | Aviat | Aviat |
| Cosmos-1.0-Difusió-Video2World-14B | Aviat | Aviat |
| Cosmos-1.0-Autoregressiu-4B | Sí | Sí |
| Cosmos-1.0-Autoregressiu-Video2World-5B | Aviat | Aviat |
| Cosmos-1.0-Autoregressiu-12B | Sí | Sí |
| Cosmos-1.0-Autoregressiu-Video2World-13B | Aviat | Aviat |
Nota
NeMo també admet el preentrenament tant per a arquitectures de difusió com autoregressives. text2world models de fonamentació.
IA de la parla
El desenvolupament de models d'IA conversacionals és un procés complex que implica definir, construir i entrenar models dins de dominis particulars. Aquest procés normalment requereix diverses iteracions per assolir un alt nivell de precisió. Sovint implica múltiples iteracions per aconseguir una alta precisió, ajustaments de diverses tasques i dades específiques del domini, garantint el rendiment de l'entrenament i preparant models per al desplegament d'inferències.
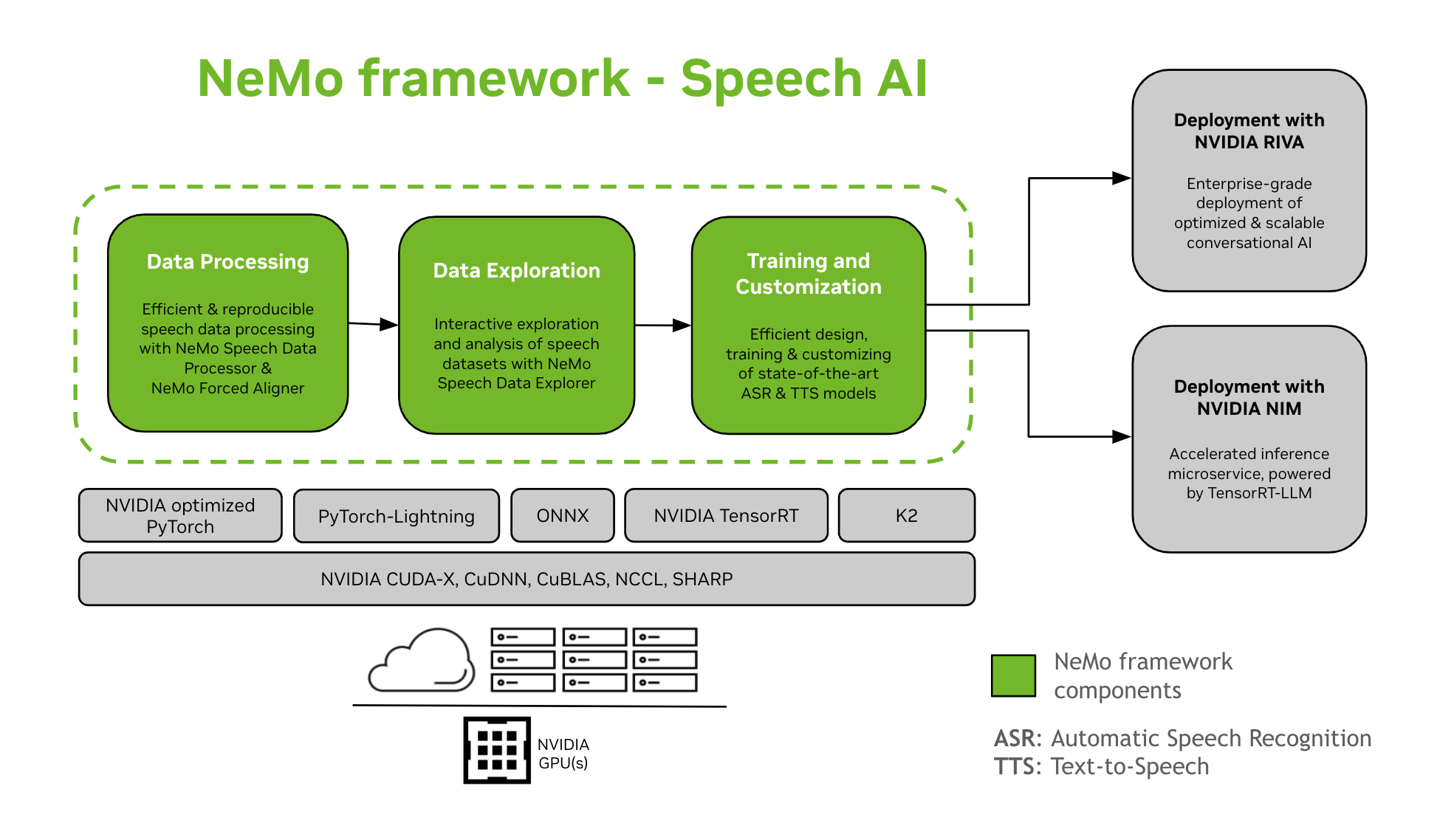
NeMo Framework proporciona suport per a l'entrenament i la personalització de models d'IA de la veu. Això inclou tasques com el reconeixement automàtic de la veu (ASR) i la síntesi de text a veu (TTS). Ofereix una transició fluida a la implementació de producció a nivell empresarial amb NVIDIA Riva. Per ajudar els desenvolupadors i investigadors, NeMo Framework inclou punts de control preentrenats d'última generació, eines per al processament de dades de veu reproduïbles i funcions per a l'exploració i l'anàlisi interactives de conjunts de dades de veu. Els components de NeMo Framework per a la IA de la veu són els següents:
Formació i personalització
NeMo Framework conté tot el necessari per entrenar i personalitzar models de veu (ASR, Classificació de la parla, Reconeixement de parlants, Diarització de l'orador, i TTS) de manera reproduïble.
Models preentrenats SOTA
- NeMo Framework proporciona receptes d'última generació i punts de control preentrenats de diversos ASR i TTS models, així com instruccions sobre com carregar-los.
- Eines de veu
- NeMo Framework proporciona un conjunt d'eines útils per desenvolupar models ASR i TTS, incloent-hi:
- Alineador forçat NeMo (NFA) per generar timest a nivell de token, paraula i segmentampde parla en àudio utilitzant models de reconeixement automàtic de parla basats en CTC de NeMo.
- Processador de dades de veu (SDP), un conjunt d'eines per simplificar el processament de dades de veu. Permet representar operacions de processament de dades en una configuració file, minimitzant el codi repetitiu i permetent la reproductibilitat i la compartibilitat.
- Explorador de dades de veu (SDE), basat en Dash web aplicació per a l'exploració i l'anàlisi interactiva de conjunts de dades de parla.
- Eina de creació de conjunts de dades que proporciona la funcionalitat per alinear àudio llarg files amb les transcripcions corresponents i dividir-les en fragments més curts que siguin adequats per a l'entrenament del model de reconeixement automàtic de parla (ASR).
- Eina de comparació perquè els models ASR comparin les prediccions de diferents models ASR pel que fa a la precisió de les paraules i a l'enunciat.
- Avaluador d'ASR per avaluar el rendiment dels models ASR i altres funcions com ara la detecció d'activitat de veu.
- Eina de normalització de text per convertir text de la forma escrita a la forma parlada i viceversa (per exemple, «31è» vs «trenta-unè»).
- Camí cap al desplegament
- Els models NeMo que s'han entrenat o personalitzat mitjançant el NeMo Framework es poden optimitzar i implementar amb NVIDIA Riva. Riva proporciona contenidors i gràfics Helm dissenyats específicament per automatitzar els passos per a la implementació amb un botó.
Altres Recursos
- NeMoEl repositori principal del NeMo Framework
- NeMo–CorreUna eina per configurar, llançar i gestionar els vostres experiments d'aprenentatge automàtic.
- Alineador NeMo: Eines escalables per a un alineament eficient del model
- NeMo-Curator: Kit d'eines de preprocessament i curació de dades escalables per a LLM
Interactua amb la comunitat NeMo, fes preguntes, rep ajuda o informa d'errors.
- Debats de NeMo
- Problemes de NeMo
Llenguatges i Frameworks de Programació
- Python: La interfície principal per utilitzar el NeMo Framework
- Pytorch: El marc de treball NeMo està construït sobre PyTorch
Llicències
- El repositori NeMo de Github està sota la llicència Apache 2.0
- NeMo Framework té llicència sota l'ACORD DE PRODUCTE D'IA D'NVIDIA. En accedir i utilitzar el contenidor, accepteu els termes i condicions d'aquesta llicència.
- El contenidor NeMo Framework conté materials Llama regits per l'Acord de Llicència Comunitària Meta Llama3.
Notes a peu de pàgina
Actualment, el suport de NeMo Curator i NeMo Aligner per a models multimodals és un treball en progrés i estarà disponible molt aviat.
Preguntes freqüents
P: Com puc comprovar si el meu sistema està afectat per la vulnerabilitat?
A: Podeu comprovar si el vostre sistema està afectat verificant la versió de l'NVIDIA NeMo Framework instal·lada. Si és inferior a la versió 24, el vostre sistema pot ser vulnerable.
P: Qui va informar del problema de seguretat CVE-2025-23360?
A: El problema de seguretat va ser reportat per Or Peles – JFrog Security. NVIDIA reconeix la seva contribució.
P: Com puc rebre futures notificacions de butlletins de seguretat?
A: Visiteu la pàgina de seguretat del producte NVIDIA per subscriure-us a les notificacions dels butlletins de seguretat i mantenir-vos informats sobre les actualitzacions de seguretat del producte.
Documents/Recursos
 |
NVIDIA NeMo Framework [pdfGuia de l'usuari Marc de treball NeMo, NeMo, Marc de treball |